| Overview | Develop | Deploy | Data |
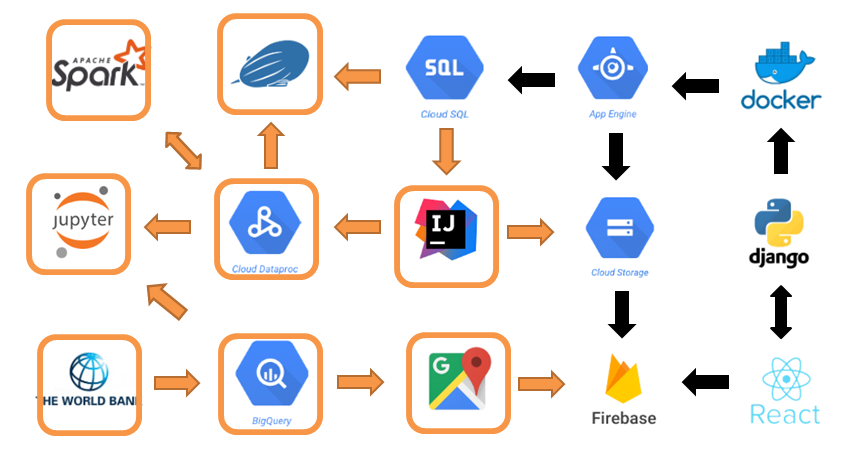
This is all of the Big Data aspects of the shared-world project. This includes:
- Data Analysis: Scala code and Zeppelin notebook of Spark programming
- Match posts to user interests: Scala jar files to output post ordered by user interests using SparkSQL
- Map of tourist-resident ratio: the sql queries and table for the interactive map
- Linear Regression Model: pyspark code and Jupyter notebook to create linear regression model using SparkML
Getting Started
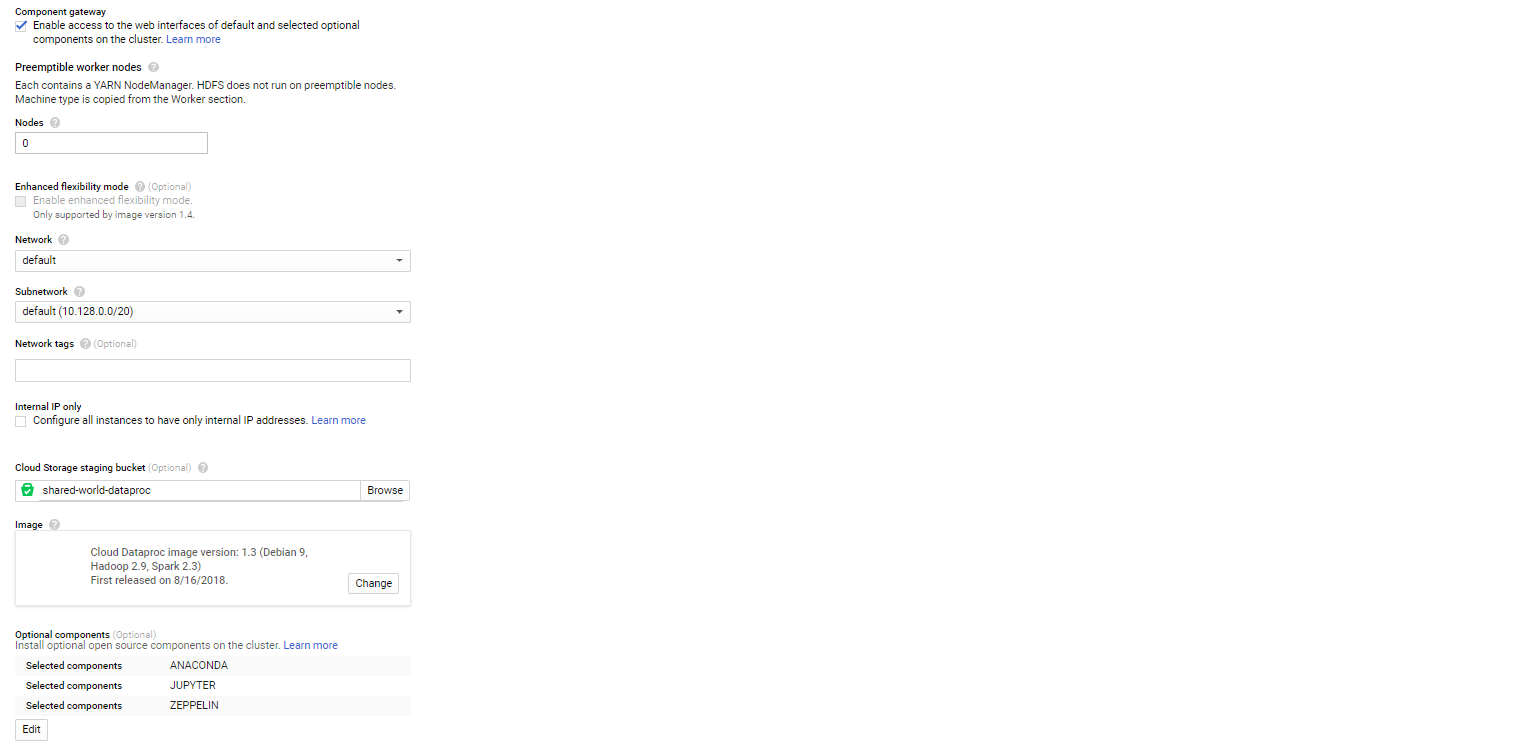
(1) Setup Dataproc cluster
(3) Dataproc Cluster for notebooks
- Create cluster on Dataproc
- Enable component gateway
- Add path to bucket for outputs
- Add Anaconda, Jupyter and Zeppelin notebook
- Once created created go to Web Interface tab and select notebook
- Once open select the desired kernel